For the first time the #CoSocialCa Mastodon server has started to struggle just a little bit to keep up with the flow of the Fediverse.


-
@mick Push and pull depend on the point of view. Would you please clarify as it isn't immediately obvious to me (it occurs to me that I do not have a good mental model of AP)?
-
We’ll do this staging first, because I am a responsible sysadmin (and I am only ever half sure I know what I’m doing.)
We’re running the default config that came with our DigitalOcean droplet, which as a single sidekiq service running 25 threads.
4/?

-
@virtuous_sloth When someone here writes a post, makes a comment, interacts with a remote post, the activity lands in the push queue, and is then distributed to other servers in the network. This is pretty active on our server but tends to clear very quickly.
The pull queue “Handles tasks such as handling imports, backups, resolving threads, deleting users, and forwarding replies.” And for some reason is getting clogged of late.
-
@mick interesting. Definitely sounds like pull would be a lot lower workload, but perhaps the push queues have a lot more resources dedicated while pull does not?
-
That article from DigitalOcean suggests that 10-15 threads = 1 GB of RAM.
We also need to give each thread its own DB connection.
In staging the DB is local, so we don’t need to worry too much about a few extra connections.
In production, we’re connected to a DB pool that will funnel the extra connections into a smaller number of connections to the DB. Our Database server still has oodles of capacity to keep up with all of this.
5/?

-
Staging server only has 2 GB of RAM but it also has virtually no queue activity so let’s give it a shot.
Having confirmed that we have sufficient resources to accommodate the increase and then picked a number out of hat, I’m going to increase the number of threads to 40.
6/?


-
No signs of trouble. Everything still hunky-dory in staging.
On to production.
If this is the last post you read from our server then something has gone very wrong.

7/?
-
@virtuous_sloth Only thing I can figure is that we’ve taken on a bunch of new followers as a server and tipped across some threshold? Or the users we follow are more chatty of late?
It did start when Eurovision began, but as a small server of Canadians idk how much Eurovision discussion we were plugged into.
A few more threads ought to help. If not, I’ll delve deeper.
-
Aaaand we’re good.

I’ll keep an eye on things over the next days and week and see if this has any measurable impact on performance one way or the other.
And that’s enough recreational server maintenance for one Friday night.

8/?

-
@mick @thisismissem so the thing that has me thinking about this is I was using activitypub.academy to view some logs. I did a follow to my server and it showed that my server continually sent duplicate "Accept" messages back. I can't tell if that's an issue with my server or with the academy. Because I can't see my logs.
-
Marco Rogersreplied to Marco Rogers on last edited by
@mick @thisismissem people told me that activity pub was very "chatty". I understand a lot better why that is now. But I now suspect that there's also a ton of inefficiency there. Because few people are looking at the actual production behavior.
-
-
@thisismissem @mick one thing I know is a problem is retries that build up in sidekiq. Sidekiq will retry jobs basically forever. And when server disappear, their jobs sit in the retry queue failing indefinitely. I'm sure larger instances with infra teams do some cleanup hear. But how are smaller instances supposed to learn about this?
-
-
@[email protected] that's definitely a problem with the sidekiq configuration then. Keeping retries forever just clogs up the queue... I can't imagine they'd be kept forever!
-
@thisismissem @mick where? Are they configurable? And again, how would I know? Is the recommended support channel complaining in mastodon until somebody tells you something that you can’t even verify?
-
Marco Rogersreplied to Marco Rogers on last edited by
@thisismissem @mick all I’m really saying is that even if I wanted to get more knowledgeable and make some decisions about how my server works, I don’t even have the kind of visibility that would facilitate making good decisions.
-
@polotek @mick @thisismissem what happened to the attempt to wire Mastodon up with OpenTelemetry? This kind of thing is what honeycomb.io is really good at exploring
-
@mick @virtuous_sloth If you run multiple sidekiqs, you can have a priority/ordwring of queues. So instead of growing the size of a single sidekiq you can have 2 or 3 smaller ones with the same total threads, but different orders of queues. This allows all of the sidekiqs to work on a temporarily large push or pull queue but makes sure that every queue is getting attention. Just be sure that “scheduler” only appears in one of the multiple sidekiq instances.
Example:
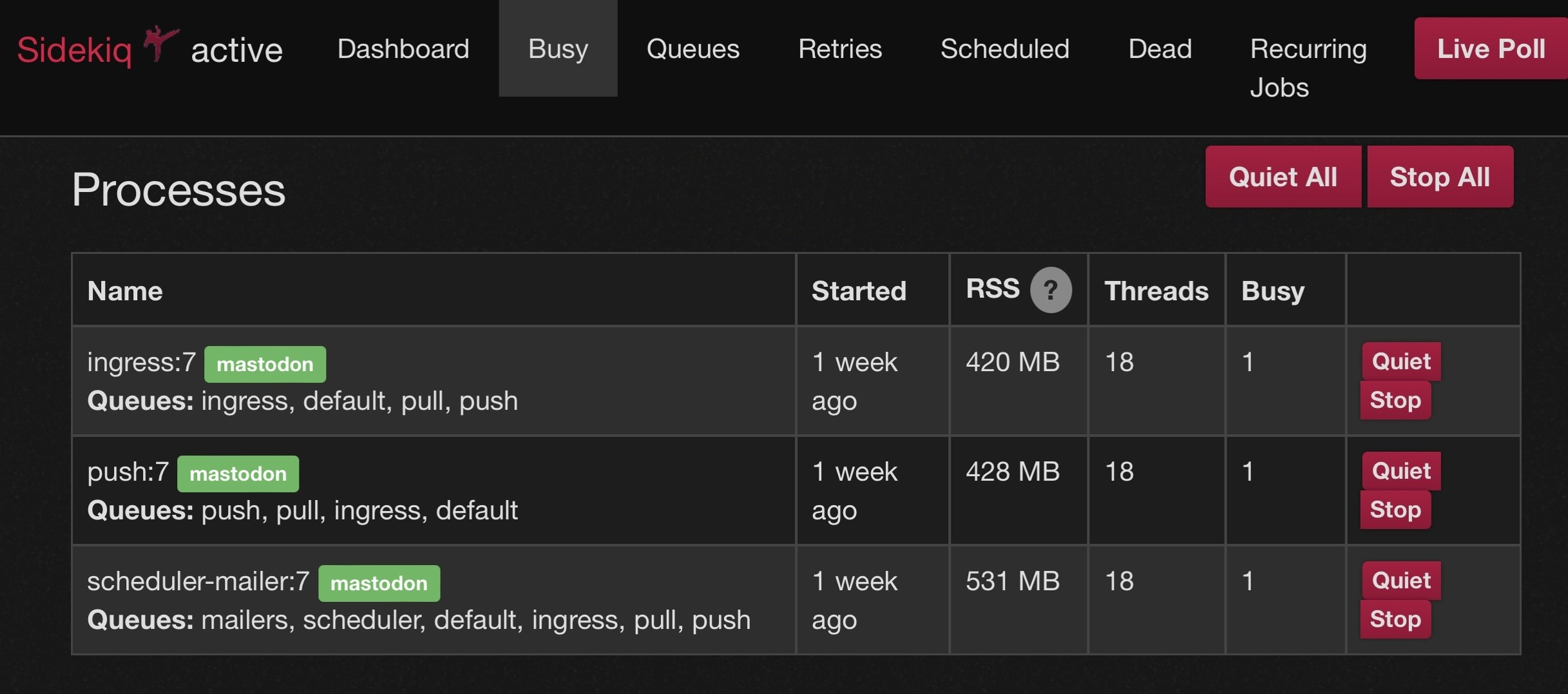
-
@KevinMarks @polotek @mick I think it's still in progress