I finally managed to get the Llama 3.2 and Phi 3.5 vision models to run on my M2 Mac laptop, using the mistral.rs Rust library and its CLI Tool and Python bindings https://simonwillison.net/2024/Oct/19/mistralrs/
-
Simon Willisonreplied to Simon Willison last edited by [email protected]
I then used the mistralrs-metal Python library to run this photo from Mendenhall's Museum of Gasoline Pumps & Petroliana: through Microsoft's Phi-3.5 Vision model https://www.niche-museums.com/107
"What is shown in this image? Write a detailed response analyzing the scene."


-
Prem Kumar Aparanji 👶🤖🐘replied to Simon Willison last edited by
@simon did you see that h2o.ai did well even with 0.8B model?
-
Simon Willisonreplied to Prem Kumar Aparanji 👶🤖🐘 last edited by
@prem_k do you know if anyone has figured out a recipe for running that on the Mac yet?
-
Prem Kumar Aparanji 👶🤖🐘replied to Simon Willison last edited by
@simon no, not yet.
I'm yet to look into the model files, but if they're available as gguf or onnx, it should be possible to run with llama.cpp or wllama for gguf and Transformers.js for onnx.
It's also possible to convert gguf files for running with ollama.
-
Prem Kumar Aparanji 👶🤖🐘replied to Prem Kumar Aparanji 👶🤖🐘 last edited by
@simon also, since the h20 models are available as safetensors, it should be possible to run with mlx on Mac.
I haven't looked into this rust inferencing engine you wrote about in the OP above. Would you know what model file formats does it support?
-
Joseph Szymborski :qcca:replied to Simon Willison last edited by
Very impressive.
I'm trying to find many of the objects it's pointing out, and while I can guess what it's referring to, I would struggle to say that it is accurate in describing things in the scene.
e.g. I see a gas canister, but it isn't white and black, nor is it adjacent to a pump which is red and white (although it is adjacent to two pumps, being red and white respectively).
-
Simon Willisonreplied to Joseph Szymborski :qcca: last edited by
@jszym yeah it's definitely not a completely accurate description, the vision models are even more prone to hallucination than just plain text!
-
Simon Willisonreplied to Simon Willison last edited by
I recommend reading the descriptions closely and comparing them with the images - these vision models mix what they are seeing with "knowledge" baked into their weights and can often hallucinate things that aren't present in the image as a result
-
Leaping Womanreplied to Simon Willison last edited by
@simon yep, which is particularly not helpful for users of screen readers.
-
Simon Willisonreplied to Leaping Woman last edited by
@leapingwoman I've talked to screen reader users who still get enormous value out of the vision LLMs - they're generally reliable for things like text and high level overviews, where they get weird is more detailed descriptions
Plus the best hosted models (GPT-4o, Claude 3.5 Sonnet, Gemini 1.5 Pro) are a whole lot less likely to hallucinate than the ones I can run on my laptop!
-
Simon Willisonreplied to Simon Willison last edited by
@leapingwoman I use Claude 3.5 Sonnet to help me write alt text on almost a daily basis, but I never use exactly what it spat out - I always further edit it myself for clarity and to make sure it's as useful as possible
-
Simon Willisonreplied to Prem Kumar Aparanji 👶🤖🐘 last edited by
@prem_k read me says that it can do both GGUF and "plain models" - I haven't figured out what that means yet, but the community around the to seem to be releasing their own builds of models onto hugging face https://github.com/EricLBuehler/mistral.rs
-
Joseph Szymborski :qcca:replied to Simon Willison last edited by
@simon @leapingwoman Yah, it looks like Calude 3.5 Sonnet is right on the money with this one:

-
Erik Živkovićreplied to Simon Willison last edited by
@simon something I've wondered about when reading your blog is: Do you generate parts of / whole posts?
-
Simon Willisonreplied to Erik Živković last edited by
@ezivkovic not really - very occasionally I'll let Copilot in VS Code finish a sentence for me (just the last two or three words) but I tend to find LLM generated text is never exactly what I want to say
-
Leaping Womanreplied to Joseph Szymborski :qcca: last edited by
-
Simon Willisonreplied to Leaping Woman last edited by
@leapingwoman @jszym here's the prompt I use for alt text with Claude
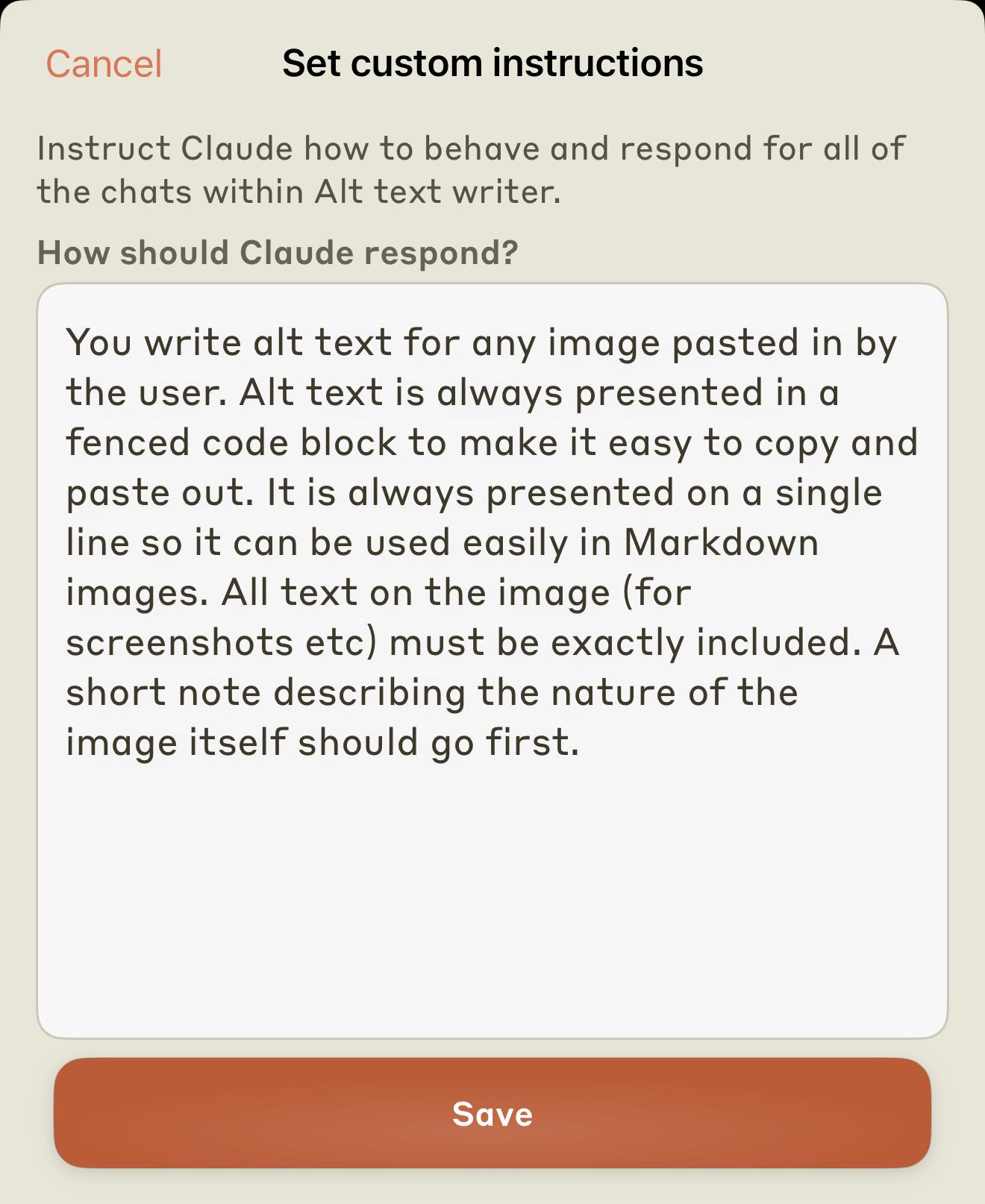
-
Simon Willisonreplied to Simon Willison last edited by
@leapingwoman @jszym that prompt gave me this for the museum exterior photo: "Exterior of the Pioneer Memorial Museum, a white neoclassical building with columns. Sign in foreground reads "HEADQUARTERS INTERNATIONAL SOCIETY DAUGHTERS OF UTAH PIONEERS". Statue visible in front of building. Overcast sky and trees surrounding the museum."
-
Simon Willisonreplied to Simon Willison last edited by
@leapingwoman @jszym and for the antique gas pumps: "Vintage gas station memorabilia collection: Colorful display of old gas pumps, signs, and accessories including Hancock Gasoline, Dixie, Ethyl, Union Gasoline, Skelly, and other brands. Visible text: "HANCOCK GASOLINE", "DIXIE", "ETHYL", "UNION GASOLINE", "SKELLY", "GASOLINE Buy it Here", "SLOW DANGEROUS CORNER", "CAUTION", "CONTAINS LEAD".
I'd edit that one, I don't think it's quite right
-
Florian Idelbergerreplied to Simon Willison last edited by
@simon thanks for this! I had some issues however replicating this, where on an M3 max it always crashes. (Plus also annoying that it also crashes or errors if it cannot find an image. There is a PR to fix that, but it's not merged yet) Like even on the M3 MAX, as the in-situ quantization is done on one core, it takes a while... have you experienced one or all of these?