Video scraping: extracting JSON data from a 35 second screen capture for less than 1/10th of a cent https://simonwillison.net/2024/Oct/17/video-scraping/
-
Video scraping: extracting JSON data from a 35 second screen capture for less than 1/10th of a cent https://simonwillison.net/2024/Oct/17/video-scraping/
I needed to extract information from a dozen emails in my inbox... so I ran a screen capture tool, clicked through each of them in turn and then got Google's Gemini 1.5 Flash multi-modal LLM to extract (correct, I checked it) JSON data from that 35 second video.
Total cost for 11,018 tokens: $0.00082635
-
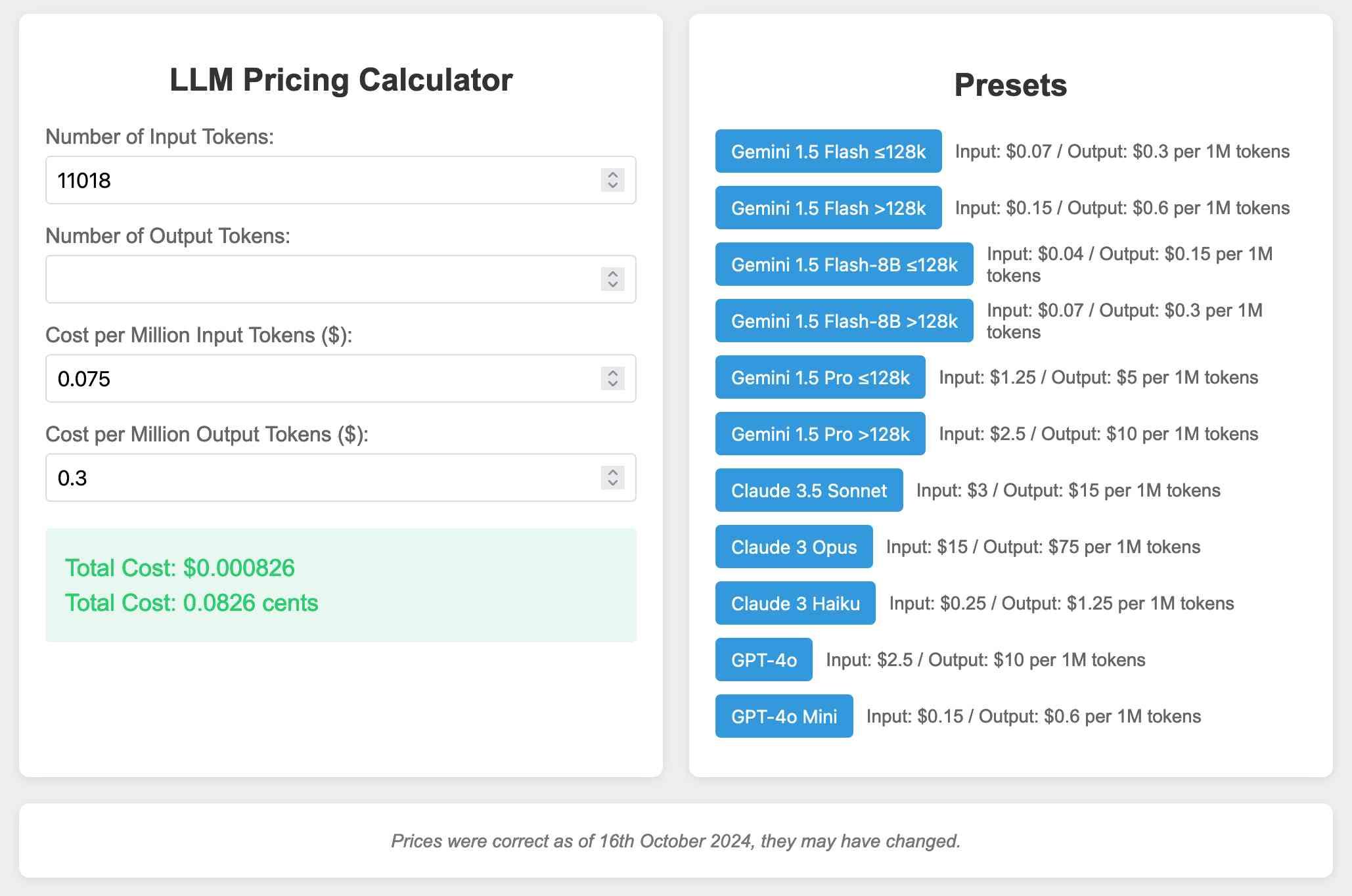
Bonus from that post: I got fed up of calculating token prices by hand, so I had Claude Artifacts spin up this pricing calculator tool with presets for all of the major models https://tools.simonwillison.net/llm-prices
-
Here's another example of multi-modal vision LLM usage: I collected the prices for the different preset models by dumping screenshots of their pricing pages directly into the Claude conversation
Full transcript here: https://gist.github.com/simonw/6b684b5f7d75fb82034fc963cc487530

-
@simon Do you use https://openrouter.ai to connect to different models, or do you use each service with it's own api and cost traccking?
-
@hoffmann I mostly use the service APIs directly - I have an OpenRouter account too but I like to stay deeply familiar with all of the different APIs as part of developing my https://llm.datasette.io tool
-
@simon Nice! You should drop a tokenizer in there for people.
-
@dbreunig I'm still frustrated that Anthropic don't release their tokenizer!
Gemini have an API endpoint for counting tokens but I think it needs an API key
-
@simon Now that you mention it, I'm curious how different each platform is with tokens and how that might affect pricing (or just be a wash)
-
@dbreunig yeah it's frustratingly difficult to compare tokenizers, which sure make price per million less directly comparable
-
@dbreunig running a benchmark that processes a long essay and records the input token count for different models could be interesting though
-
@simon At what environmental cost though?
-
Simon Willisonreplied to axleyjc last edited by [email protected]
@axleyjc I'd love to understand that more
In particular, how does the energy usage of running that prompt for a few seconds compare to the energy usage of me running my laptop for a few minutes longer to achieve the task by hand?
-
@axleyjc I was using Gemini Flash here which is a much cheaper, faster and (presumably) less energy intensive model than Gemini Pro
There's also the new Gemini Flash 8B which is cheaper still, and the "8B" in the name suggests that the parameter count may be low enough that it could run on a laptop if they ever released the weights (I run open 8B models locally all the time)
-
@simon great documentation ... Any details on accuracy? How much did you have to clean up the output and did you have to check it all by hand?
-
@th0ma5 I checked it all, didn't take long (I watched the 35s video and scanned the JSON) - it was exactly correct
-
@simon Is it also possible to calculate how much energy these things use, and some comparisons of what that's equivalent to? I hear that AI is energy intensive but I have zero concept of what that means in reality for a single "thing" like this.
-
@philgyford if that's possible I haven't seen anyone do it yet - the industry don't seem to want to talk specifics
GPUs apparently draw a lot more power when they are actively computing than when they are idle, so there's an energy cost associated with running a prompt that wouldn't exist if the hardware was turned on but not doing anything
-
Video scraping in Ars Technica! https://arstechnica.com/ai/2024/10/cheap-ai-video-scraping-can-now-extract-data-from-any-screen-recording/
-
@superFelix5000 @th0ma5 right - the single hardest thing about learning to productively work with LLMs is figuring out how to get useful results out of inherently unreliable technology