I added multi-modal (image, audio, video) support to my LLM command-line tool and Python library, so now you can use it to run all sorts of content through LLMs such as GPT-4o, Claude and Google Gemini
-
I added multi-modal (image, audio, video) support to my LLM command-line tool and Python library, so now you can use it to run all sorts of content through LLMs such as GPT-4o, Claude and Google Gemini
Cost to transcribe 7 minutes of audio with Gemini 1.5 Flash 8B? 1/10th of a cent.

You can now run prompts against images, audio and video in your terminal using LLM
I released LLM 0.17 last night, the latest version of my combined CLI tool and Python library for interacting with hundreds of different Large Language Models such as GPT-4o, Llama, …
(simonwillison.net)

-
@simon Since you have the tokens readily available what do you think about including the pricing calculator directly inside `llm`?
aider is doing a similar thing by directly showing you how much you were billed for each response. -
Andrea Borrusoreplied to Simon Willison last edited by
@simon first of all thank you very much.
In your llm logs output you have "total_tokens". I do not have it, I have a lot of time "totalTokenCount": 3522"
Am I doing something wrong

-
Simon Willisonreplied to Andrea Borruso last edited by
@aborruso that output is different for different models - I have a future plan to normalize those and store them separately in the database
-
@ame I want to do a bit more with token accounting - maybe store them in separate database columns - but I'm not so keen on doing the price calculations in the tool because I can't promise correct results, since the prices often change sometimes without any warning
I'd be OK outsourcing that to a plugin though
-
Simon Willisonreplied to Simon Willison last edited by [email protected]
If you are still LLM-skeptical but haven't spent much time thinking about or experimenting with these multi-modal variants I'd encourage you to take a look at them
Being able to extract information from images, audio and video is a truly amazing capability, and something which was previously prohibitively difficult - see XKCD 1425 https://xkcd.com/1425/
-
Simon Willisonreplied to Simon Willison last edited by
The LLM Python library supports attachments now as well https://llm.datasette.io/en/stable/python-api.html#attachments
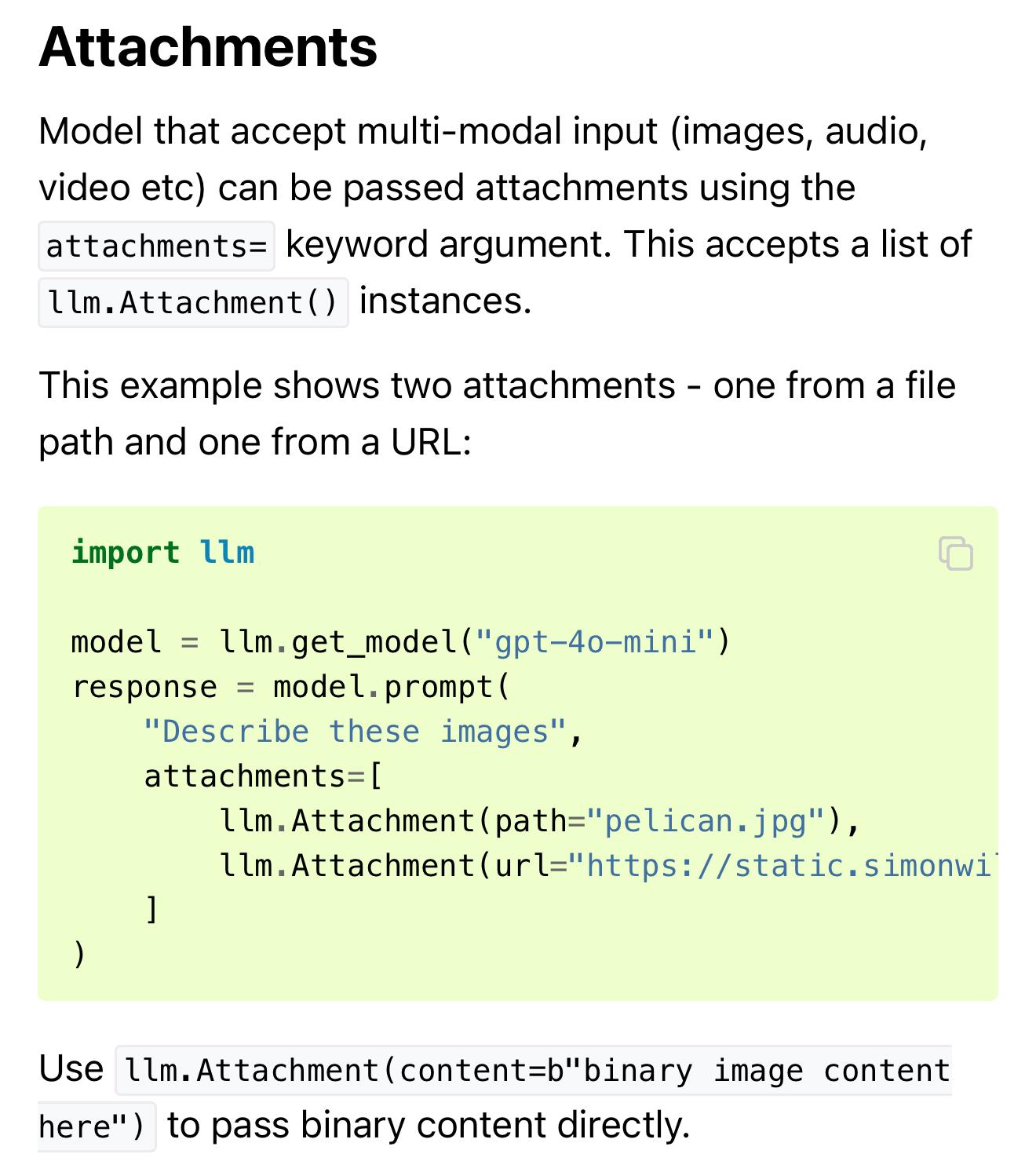
-
Prem Kumar Aparanji 👶🤖🐘replied to Simon Willison last edited by
@simon neat!
Where can I look at the code behind this function?
-
Simon Willisonreplied to Prem Kumar Aparanji 👶🤖🐘 last edited by
@prem_k more docs here: https://llm.datasette.io/en/stable/plugins/advanced-model-plugins.html#attachments-for-multi-modal-models
Implementations are spread out across different plugins, eg https://github.com/simonw/llm/blob/a44ba49c21f8d4ac30c8e41bfa5599c258ce53cc/llm/default_plugins/openai_models.py#L338 and https://github.com/simonw/llm-gemini/blob/ce82727a6950c7769a8e40bf030591d0e6f83e5e/llm_gemini.py#L135
-
@simon Note that some of us are skeptical for reasons such as the exploitation of creative folks, the copyright infringements at scale, the hype cycle created by venture capital, the impact it has on misinformation and the ads space, and so on. Some of the tech is cool no doubt.
-
@djh those are all very valid reasons to be skeptical!
The only reason I'll consistently push back at is the idea that these things aren't useful at all
-
@djh @simon
Some are also skeptical because research demonstrates that LLMs are not reasoning
https://youtu.be/TpfXFEP0aFsbut instead are regurgitating memorised answers
https://youtu.be/y1WnHpedi2Aamong other problems of which users should be made aware before placing all their trust in the generated response
https://youtu.be/7bmhjt1cpRs -
-
@simon note that the capability is dangerously untrustworthy (and when you don't mention this or any of the other concerns like environmental harm or creative theft, "check this out if you're still skeptical" comes across as condescending) https://www.engadget.com/ai/openais-whisper-invents-parts-of-transcriptions--a-lot-120039028.html
-
@aburka from my post:

-
@simon I mean, they've been evaluated, they're not suitable. What's left to explore?
-
@aburka since you ask, I did dig around in one of the papers underlying the other story and found it was partly about how much better whisper v3 was compared to v2 https://fedi.simonwillison.net/@simon/113380266881069878
-
Simon Willisonreplied to Simon Willison last edited by
@aburka generally though the most important thing about using LLMs (and AI/machine learning models in general) is figuring out how to make effective and responsible use of inherently unreliable technology
Generating unreviewed medical transcripts and then throwing away the original recordings is NOT responsible
-
@simon Does video work? I tried both Gemini pro and flash, but I only got some error message. Do I need a paid account to use video scraping? (Image works as expected.)
-
@xsc video should work, what file format were you trying? Currently needs to be less than 20MB - that's a temporary limitation of my llm-gemini plugin

