I just deleted 1,372 disks from Google cloud and 7 project spaces.
-
Scott Williams 🐧replied to Scott Williams 🐧 last edited by [email protected]
@Viss @arichtman @mttaggart I literally wrote my own CNI before I realized what I was doing just trying to get a reliable network service that I could proxy between containers with it. It constantly called etcd to splice in config updates to nginx with regex on changes on each of the hosts with logic to proxy sub paths, etc.
-
Scott Williams 🐧replied to Scott Williams 🐧 last edited by
@Viss @arichtman @mttaggart I never published it because it felt so dirty and I didn't want to maintain it and it was a problem I didn't have to solve with Kubernetes.
-
@arichtman @Viss @mttaggart I was there for the 1.0 release of Kubernetes and that's a very reductionistic take on it. This was before Google was full blown bad guy and I'm sure they had business reasons, but Kubernetes solved problems that Mesos and Swarm struggled to solve. Mesos was badly fragmented with Twitter basically having its own fork. It knew how to scale big but was a struggle at small. Swarm had the opposite problem. Controlled by one company and didn't scale well.
-
Scott Williams 🐧replied to Scott Williams 🐧 last edited by
@arichtman @Viss @mttaggart Keep in mind doing so created a lot of competition for them. This was back when Red Hat openshift was an awkward Heroku PaaS competitor. It was great publicity for GKE, to be sure, but it wasn't without significant realized risk to open source it.
-
@arichtman @Viss @mttaggart I liked cilium in concept because you could eliminate the need for kube-proxy, but it also comes with some foot-rake opportunities and quirks in places that other CNIs didn't.
-
@arichtman @Viss @mttaggart Layer2/3 routing with MetalLB is very easy and simple to setup, but you need proper BGP for routing beyond that.
If you already have established network infra then you can use multus with network bridging at the host level and use more traditional sys admin networking tools to do it, using vlans, ippools, dhcp, etc.
-
Scott Williams 🐧replied to Viss last edited by [email protected]
@Viss @arichtman @mttaggart I utilize env injection via encrypted vaults in a CI context, but so the same code is deployed in production but with different credentials and endpoints and none of those credentials living in git, container images, etc. - the dev, staging, production model and all.

The Twelve-Factor App
A methodology for building modern, scalable, maintainable software-as-a-service apps.
(12factor.net)
-
Scott Williams 🐧replied to Ariel last edited by [email protected]
@arichtman @Viss @mttaggart Depending on your Kubernetes distro, that is largely true. Openshift and Rancher include optional operators for it.
The one Rancher ships is based on vals and supports sops.
GitHub - digitalis-io/vals-operator: Kubernetes Operator to sync secrets between different secret backends and Kubernetes
Kubernetes Operator to sync secrets between different secret backends and Kubernetes - digitalis-io/vals-operator

GitHub (github.com)
Red Hat's is ESO:
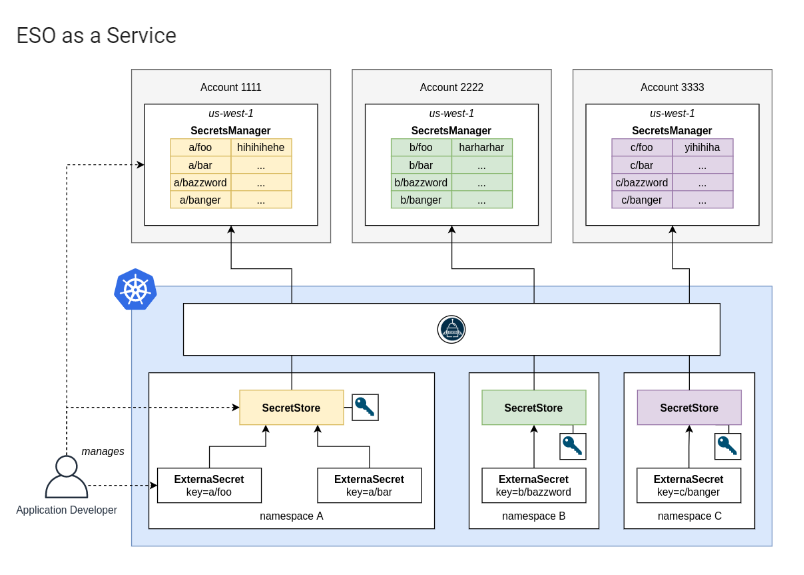
How to Setup External Secrets Operator (ESO) as a Service
This guide makes an attempt to show one of the many methods we can utilize to store "sensitive" data in an external secrets management system such as AWS Secrets Manager, retrieve that data via the ESO and have them stored in Kubernetes secrets for applications to use.
(www.redhat.com)
-
Scott Williams 🐧replied to Scott Williams 🐧 last edited by
@arichtman @Viss @mttaggart The short of it is, if you care about Kubernetes security, you're going to pay up for Rancher or Openshift support. Rancher RKE2 was originally written specifically around FIPS compliance for government vendors and expanded the customer base from there.
-
@Viss @arichtman @mttaggart To be fair, you're not wrong for a whole lot of use cases. If you built your empire on a LAMP stack, that doesn't translate well in a scalable way in a Kubernetes world because it was stateful and built for vertical scaling. Forcing that into Kubernetes means retooling some core architectural things for the stack for an outcome that might not be demonstrably better.
-
@vwbusguy @arichtman @mttaggart unless youre dealing with like, dozens or hundreds of containers that are geographically distributed, i get the impression kubernetes is just massive overhead and lots of extra attack surface. I can see how in narrow circumstances it can be useful, but so far literally every single k8s deployment ive seen is "way more overhead and complexity and attack surface, for not enough benefit"
-
@Viss @vwbusguy @arichtman I believe this is generally correct. The scale at which its utility becomes apparent will never be achieved by the vast majority of those who use it. The choice was informed by hype and a desire to believe they would one day require, as K8s puts it, "planetary scale."
-
@Viss @arichtman @mttaggart Again, I agree with you that this is true for a lot of use cases and shops. That said, you can't pretend that things were gloriously secure en masse in the older days of LAMP, Tomcat, and ASPX. Moving to Kubernetes in some cases allowed for better hygiene in general around secrets, hardening, and idempotency. For stuff like multi-tenant JupyterHub, Kubernetes is highly practical. For serving your company's blog - maybe not.

Project Jupyter
A multi-user version of the notebook designed for companies, classrooms and research labs
(jupyter.org)
-
@vwbusguy @arichtman @mttaggart thats the tug though. everyones hamfisting it in everywhere, using it for their core business infra or making it part of ci/cd pipelines. nobody is using it 'the right way'
-
Scott Williams 🐧replied to Taggart :donor: last edited by
@mttaggart @Viss @arichtman This was definitely true in some shops. I actually remember hearing a Red Hat person advising a customer once, roughly nine years or so ago, that what they wanted OpenShift for could be done better on some regular machines running RHEL. I admired the honesty and restraint from oversell in that particular moment.
-
Scott Williams 🐧replied to Viss last edited by [email protected]
@Viss @arichtman @mttaggart CI/CD pipelines makes sense - not having designated hardware sit idle when workers aren't running, the worker agents can go away when the job is done leaving only intended artifacts meaning less attack vector for workers, idempotency, etc.
Of course you don't *have* to do it this way, but there's a clear case to be made.
-
@vwbusguy @arichtman @mttaggart that description is not how i have seen it deployed, though
-
@Viss @arichtman @mttaggart That's how I have it deployed
 . All on prem with Jenkins and Rancher RKE2 k8s backends.
. All on prem with Jenkins and Rancher RKE2 k8s backends. -
Taggart :donor:replied to Scott Williams 🐧 last edited by
@vwbusguy @Viss @arichtman This conversation is quite the piece of evidence that you are the exception to the rule. Your knowledge is impressive, and rare. Certainly moreso than orchestrated container deployments. Y'all are both right.
-
@mttaggart @vwbusguy @arichtman this is just the 2024 version of
- there is a 'way to do it right'
- most people do not do it that way
- the thing is almost certainly being used when it doesnt need to be
- the folks deploying the thing in most cases are not familiar enough with it, or architecture in general to adquately harden it
-- or they just dont care to, usually because complianceit used to be lamp, now its containers