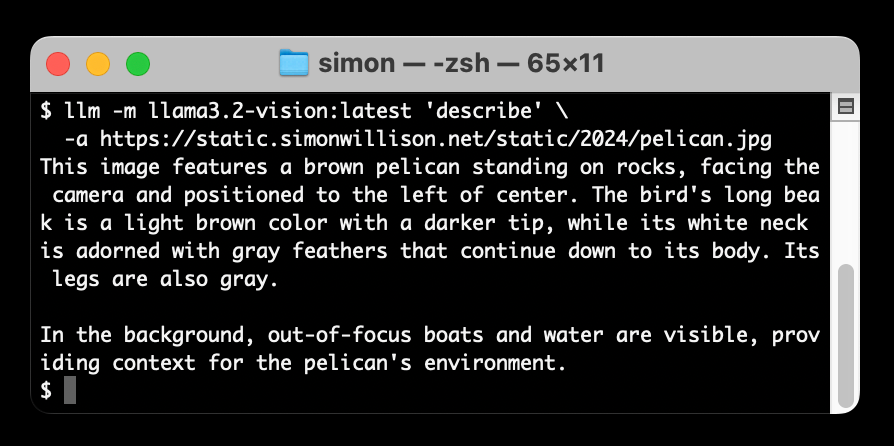
Thanks to the combo of Ollama and the llm-ollama plugin you can now run Meta's Llama 3.2 Vision image model (7.9GB) on a Mac and use it to run prompts against images https://simonwillison.net/2024/Nov/13/ollama-llama-vision/
-
Thanks to the combo of Ollama and the llm-ollama plugin you can now run Meta's Llama 3.2 Vision image model (7.9GB) on a Mac and use it to run prompts against images https://simonwillison.net/2024/Nov/13/ollama-llama-vision/


-
Anant Shrivastava aka anantshrireplied to Simon Willison last edited by
@simon just curious what do you suggest for image creation besides stablediffusion. Local install model wise.
-
Simon Willisonreplied to Anant Shrivastava aka anantshri last edited by
@anant I don't do much work with image models myself - I've heard the current state-of-the-art is FLUX1.1 but I've not tried running that on my own laptop yet.
-
@simon Curious how you’re running Ollama - is it just in your laptop or you have some beefy server running it?
-
@jmalonzo just on my laptop, it's a M2 Max with 64GB of RAM so it's pretty good for small and medium sized models
Any model that needs more than 32GB of RAM tends to mean I can't easily run other RAM-hungry apps like VS Code and Firefox
-
@simon the 90B (55GB) might confuse people.
You do need ~88GB of RAM, not counting your context window, just to run the 90B model size. So 128 GB of RAM, or else you are going to get 1 token per 30 to 45 seconds or more of output while everything swaps around.
That small model is going to run very, very well on any M-series Mac with enough RAM.
-
@webology thanks, updated that to say "Or the larger 90B model (55GB download, likely needs ~88GB of RAM) like this:"
-
@simon any idea of that 90b will fit inside the 64GB memory footprint of an M series Mac?
-
@soviut I don't think so, see note from Jeff here https://mastodon.social/@webology/113473521029326631