[nodebb-plugin-glossary] Glossary Plugin for NodeBB
-
@baris I found the issue (for my case). In
library.jsthe regex statement looks for insensitive as belowkeyword.nameRegex = XRegExp(`(?:^|\\s|\\>|;)(${keyword.name})`, 'gi');I've changed it to
keyword.nameRegex = XRegExp(`(?:^|\\s|\\>|;)(${keyword.name})`, 'g');Which works fine for my use case (virtually all of the acronyms I have are in upper case). However, lower case words are still affected.
Issue with over gratuitous regex · Issue #3 · NodeBB/nodebb-plugin-glossary
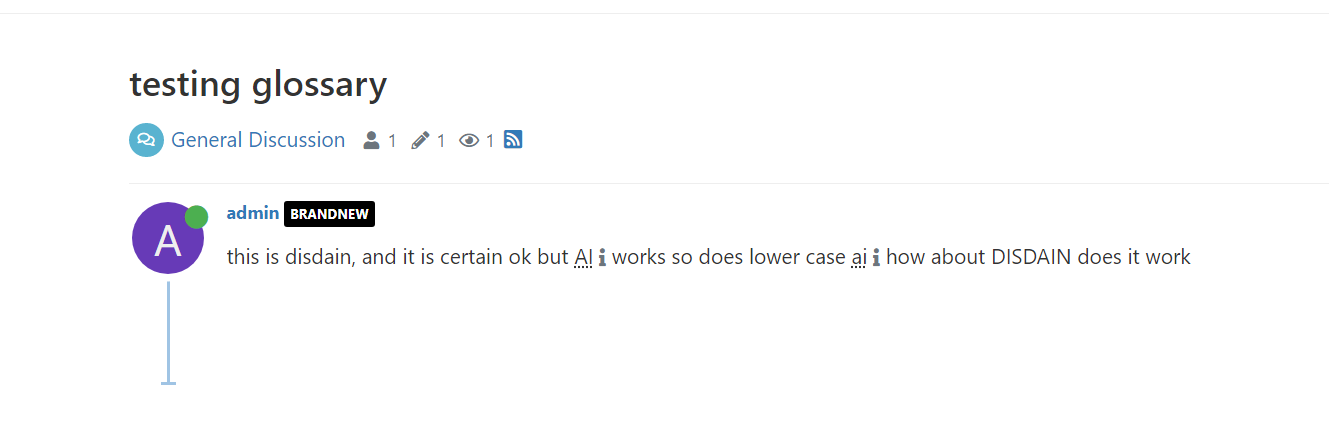
One thing I've noticed here is that the plugin seems gratuitous in terms of REGEX - it's matching on any part of the word, meaning things like AI is detected inside disdain and certain - is there any way we can have a setting that looks ...

GitHub (github.com)
-
-
@baris From what I see, the plugin is actually firing on whole words

In this case, it's matching on
bitsas well asbit(which it should)And also matching on
devinsidedevil
EDIT: Sorry - this was due to the CSV import I have... Ignore that
")
-
@baris another suggestion would be to empty the table storing the glossary items. When you import 1000 plus from a CSV it's very clunky to have to delete them all one by one
if you need to.Allow option to empty glossary content · Issue #5 · NodeBB/nodebb-plugin-glossary
A suggestion would be to empty the table storing the glossary items. When you import 1000 plus from a CSV it's very clunky to have to delete them all one by one 🙂 if you need to.
GitHub (github.com)
-
-
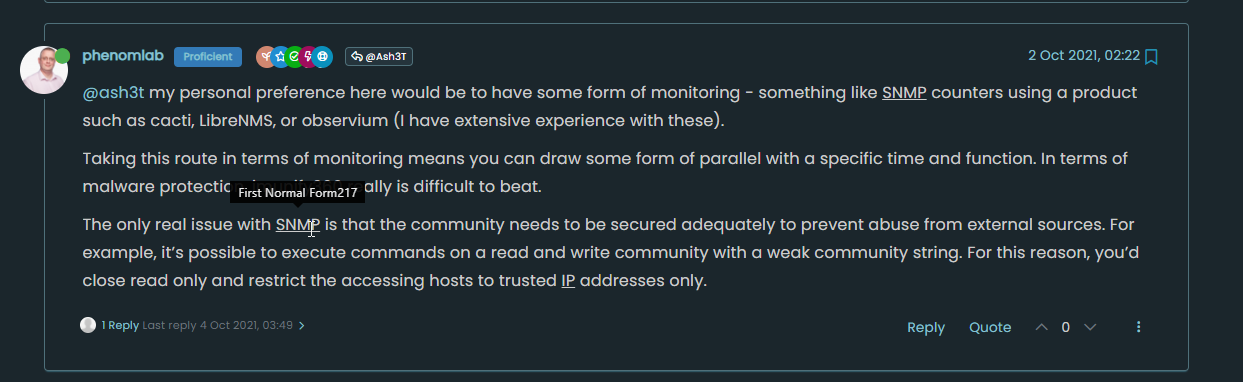
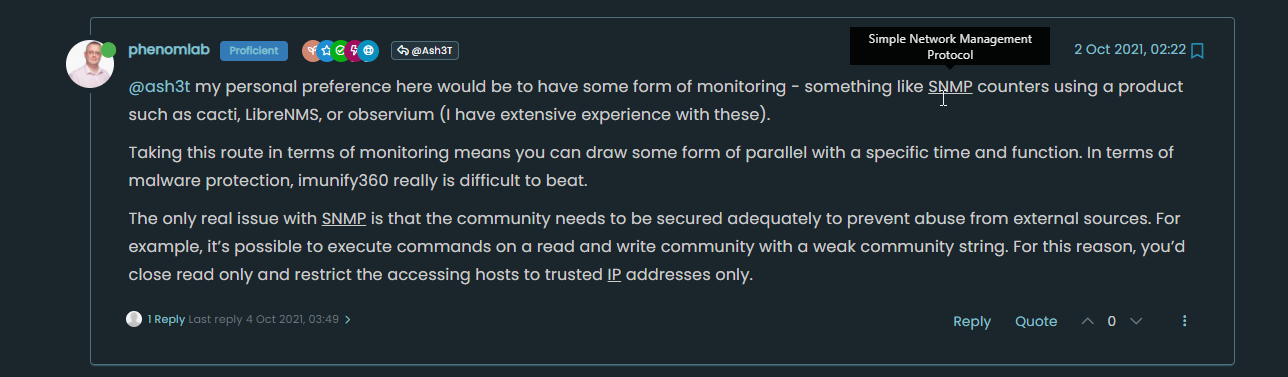
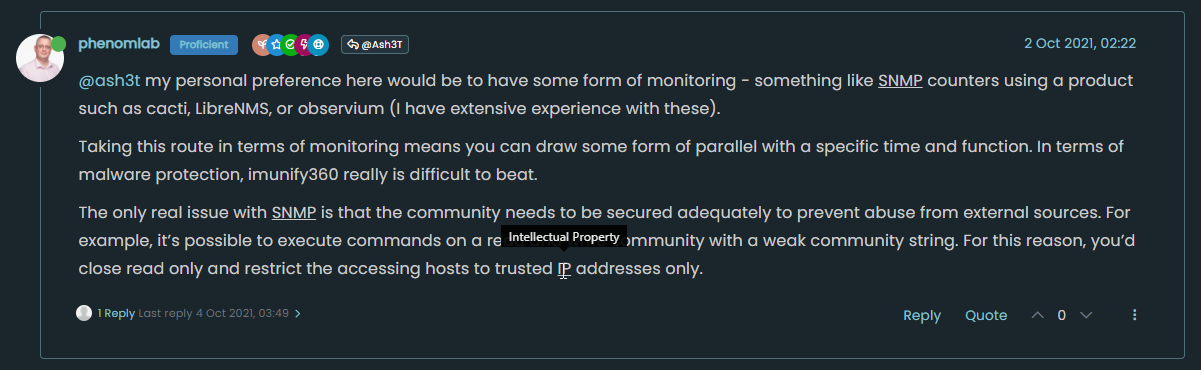
@baris Thanks. I spotted a bug in 0.6 when performing a large import. The mapping being returned should be (for example
SNMPSimple Network Management Protocolcomes back withSNMPsomething completely wrong)Examples
and
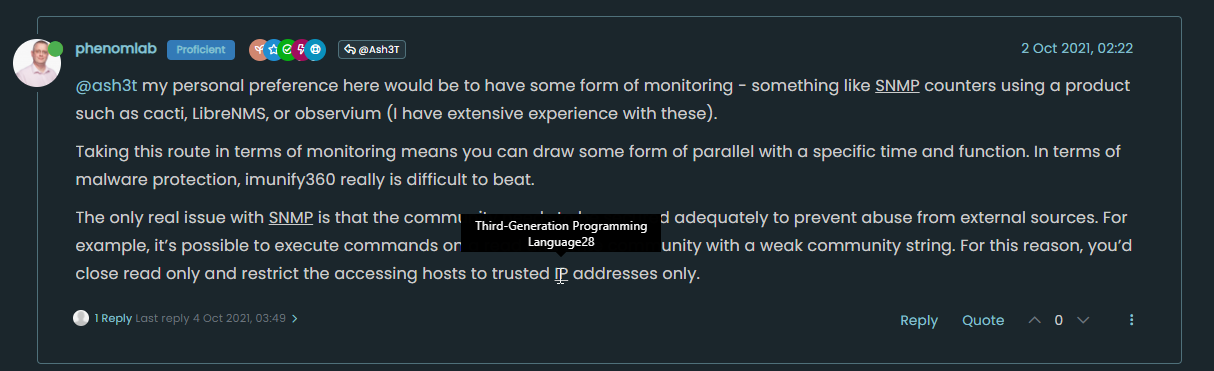
Not sure if my data is incorrect (I'll check), but wanted to report this in case it is actually an issue. Reverting back to 0.5 the issue is not present
and
So, I think there is a bug somewhere
-
-
add csvtojson support · Issue #7 · NodeBB/nodebb-plugin-glossary
use https://www.npmjs.com/package/csvtojson instead of custom code
GitHub (github.com)
-
I updated the plugin to use https://www.npmjs.com/package/csvtojson so it is using the csv spec from https://www.loc.gov/preservation/digital/formats/fdd/fdd000323.shtml
-
@baris This doesn't seem to work for me at all using the latest version sadly. It doesn't matter which format I use, the import always seems to work, but exhibits the same issues as I highlighted earlier. Version
0.5does not have these issues from what I can tell. -
-
-
-
Added i18n, feel free to send pull requests to add new languages. https://github.com/NodeBB/nodebb-plugin-glossary/commit/616ab500cd6ad906ace7eb7510f7f08789d3515d